
Hive
satya - 7/15/2019, 12:18:10 PM
Briefly
A mechanism to see distributed big data as a set of tables
Run SQL (HiveQL) against that data
Have drivers like JDBC so that languages can execute SQL queries while taking advantage of distributed data and distributed processing
Uses a Hive metastore in a relational database to register schemas and where the physical paths are for those tables
satya - 7/15/2019, 12:21:39 PM
Architecture
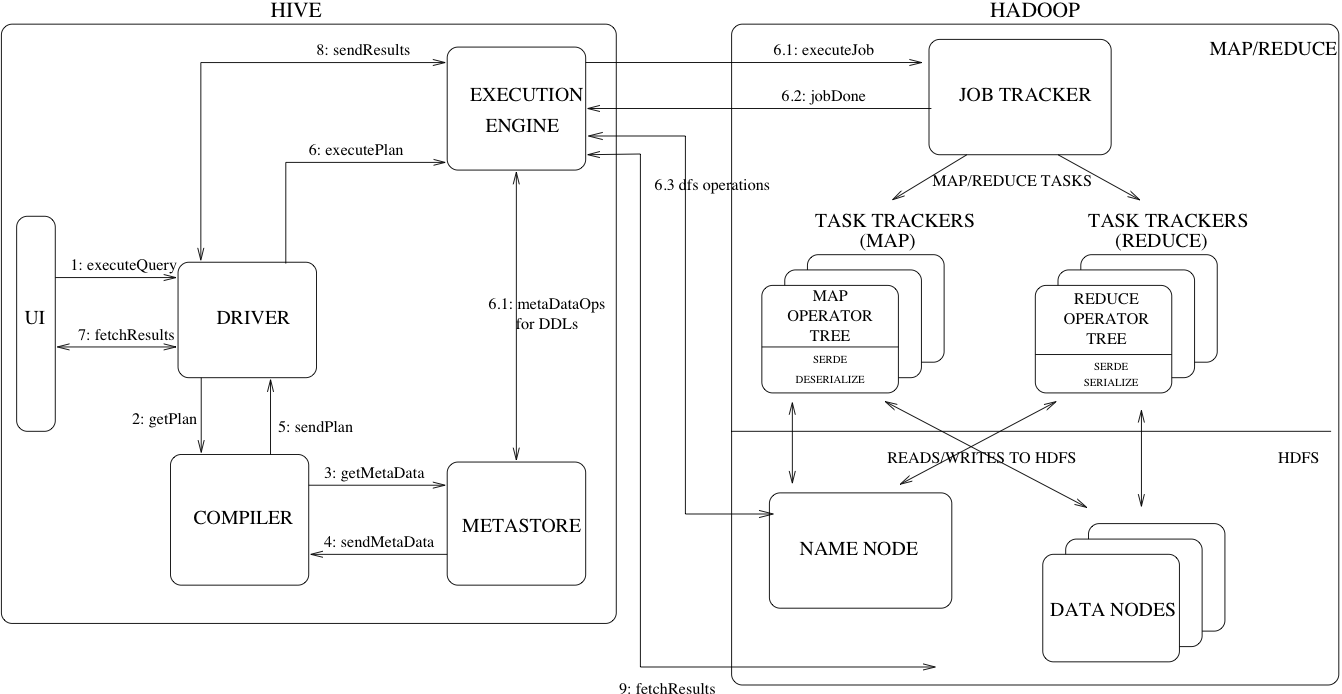
satya - 7/15/2019, 12:21:58 PM
Hive is not a scripting language like Pig: FYI
Hive is not a scripting language like Pig: FYI
satya - 7/15/2019, 7:36:52 PM
Pig and Hive answer to SQL on Hadoop
They use Yarn underneath
They use mapreduce
they are fundamentally batch jobs/operations
Good for long running jobs/processes
satya - 7/15/2019, 7:39:03 PM
SQL alternatives
These are inspired by the need for real time queries
Inspired by Googl'e Big Query
They have a flavor of MPP (Massively Parallel processing) of relational databases like in Postgres
These use their own "distributed processing" protocols and may diverge from Yarn
they may use lot of memory
satya - 7/15/2019, 7:43:52 PM
Examples
Cloudera Impala - MPP architecture uses its own clustering (not YARN or MapReduce) for processing
Apache Tez - An efficient application processing framework abstraction on top of Yarn. Can be used as an engine for Hive or Pig
Apache Hawq - A Pivotal solution that morphed from postgress MPP
Apache Drill - A direct implementation of BigQuery
Presto - Brand new kid on the block. they all support federated queries across various sources