Kafka
Kafka
satya - 7/21/2017, 9:56:54 AM
Few video tutorials on Kafka a youtube link
satya - 7/21/2017, 10:02:01 AM
So what is it
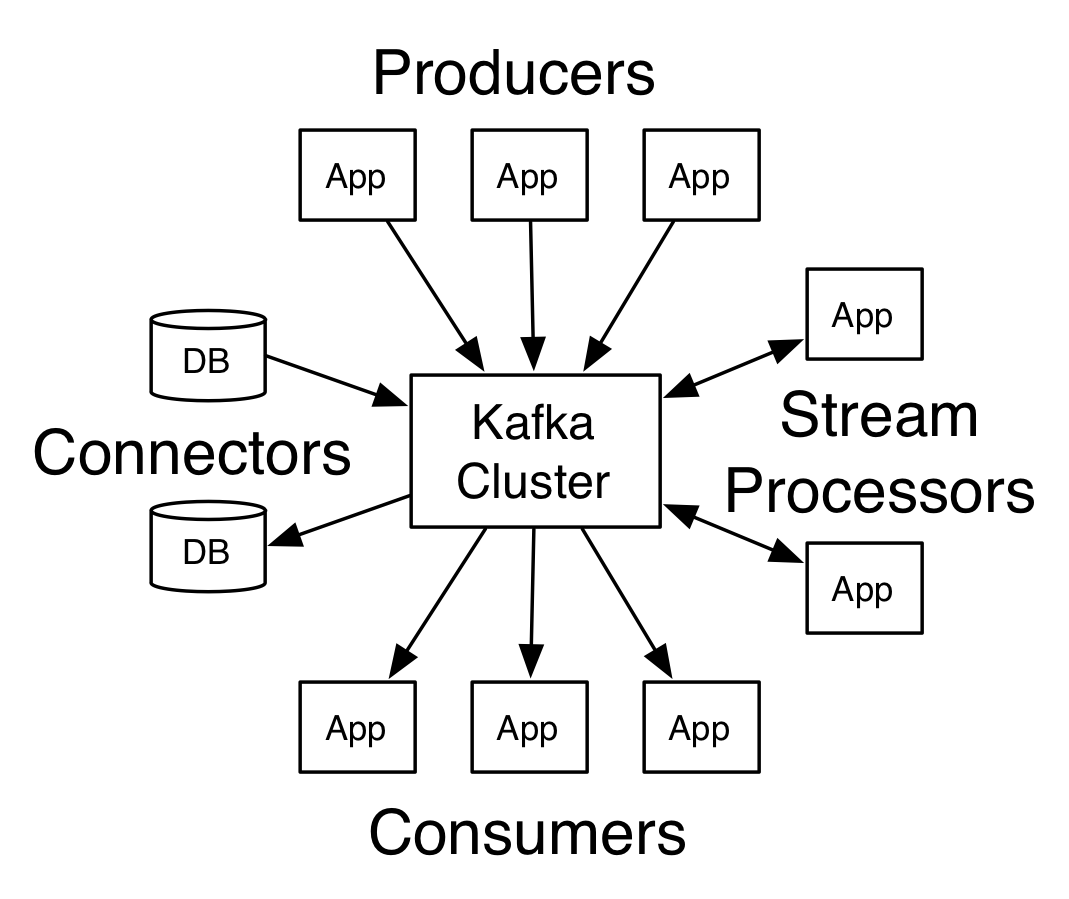
Kafka? is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
PUBLISH & SUBSCRIBE: to streams of data like a messaging system
PROCESS: streams of data efficiently and in real time
STORE: streams of data safely in a distributed replicated cluster
satya - 7/21/2017, 10:04:32 AM
Briefly
satya - 7/21/2017, 10:45:45 AM
This is fundamentally messaging framework like IBM MQ perhaps tuned to the iOT like world
This is fundamentally messaging framework like IBM MQ perhaps tuned to the iOT like world
satya - 7/21/2017, 10:47:01 AM
Likely use cases
Apply as a component of iOT
Turn an enterprise state changes as a special case of iOT for most current data in real time
Real time enable an enterprise
it is easier imagined than done
It may be component of an overall enterprise iot framework
satya - 7/21/2017, 10:49:09 AM
Clustering provides fault tolerance
Clustering provides fault tolerance
satya - 7/21/2017, 10:50:43 AM
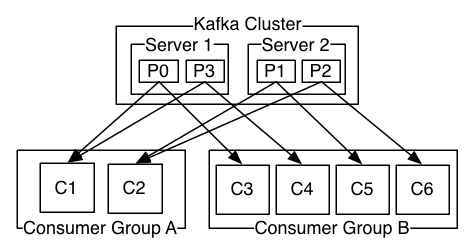
Consumers are seen as groups and messages are delivered to them for load balancing
satya - 7/21/2017, 10:52:43 AM
queues help you scale with workers
queues help you scale with workers
satya - 7/21/2017, 10:53:01 AM
pub-sub has no inherent scaling primitives
pub-sub has no inherent scaling primitives
satya - 7/21/2017, 10:58:34 AM
Kafka says
it can allow both queuing and pub/sub models
stronger ordering
provide both ordering guarantees and load balancing over a pool of consumer processes. This is achieved by assigning the partitions in the topic to the consumers in the consumer group so that each partition is consumed by exactly one consumer in the group. By doing this we ensure that the consumer is the only reader of that partition and consumes the data in order. Since there are many partitions this still balances the load over many consumer instances. Note however that there cannot be more consumer instances in a consumer group than partitions.
taking storage seriously and allowing the clients to control their read position, you can think of Kafka as a kind of special purpose distributed filesystem dedicated to high-performance, low-latency commit log storage, replication, and propagation.
Has a special API for processing streams and output them
Effectively a system like this allows storing and processing historical data from the past.
By combining storage and low-latency subscriptions, streaming applications can treat both past and future data the same way. That is a single application can process historical, stored data but rather than ending when it reaches the last record it can keep processing as future data arrives. This is a generalized notion of stream processing that subsumes batch processing as well as message-driven applications.
satya - 7/21/2017, 1:50:01 PM
Main company that produces and supports Kafka: Confluent
satya - 7/21/2017, 1:55:16 PM
Key Questions and Further research
1. Is there a browser to look at the events and documentation that talks to the payloads of these events at an enterprise level?
2. How is security handled between producers and consumers
3. Can ftp and batch processing be re imagined through Kafka? what does that model look like? Has anyone done it?
4. It is said that the streaming API supports distributed state for processing clients. What does it mean? How does this work? What problems does this paradigm solve?
5. As it supports multiple readers on a queue (or a stream) it is more close to a distributed file system with "long" processing. See how this enables new applications
6. How does replay work in this scenario? how is this better suited for exception handling of batch jobs where record level errors can be handled.
7. How is the company confluent is re-imagining the enterprise? what products are they offering? is this a new space?
satya - 7/21/2017, 1:57:15 PM
Fundamental differences to queuing systems
1. Persistent long term storage for events
2. Multiple readers
3. Distributed scalable implementation
4. Bringing together batch and stream processing for low latency
5. A very large eco system
satya - 7/21/2017, 7:18:57 PM
What you have is a persistent distributed database of events
What you have is a persistent distributed database of events
satya - 7/21/2017, 7:26:18 PM
Is there a browser or viewer for Kafka events
Is there a browser or viewer for Kafka events
satya - 7/21/2017, 7:31:56 PM
Here is a tool called Kafka Manager
satya - 7/21/2017, 7:33:27 PM
Kafka UI tools Kafka Manager
Kafka UI tools Kafka Manager
satya - 7/21/2017, 7:37:06 PM
Landoop, Kafka Manager, Kafka Tool
Landoop, Kafka Manager, Kafka Tool
satya - 7/21/2017, 7:44:20 PM
Zookeeper is a distributed configuration tree for holding key value pairs
Zookeeper is a distributed configuration tree for holding key value pairs
satya - 7/21/2017, 7:46:50 PM
Zookeeper and redis
Zookeeper and redis
satya - 7/21/2017, 7:53:21 PM
Here is a good summary of zookeeper
satya - 7/21/2017, 7:54:43 PM
Zookeeper is in designed to be distributed and fault tolerant
where as redis is an in memory data structure server that is available to multiple clients. One approach people are using is to use Zookeeper to make redis fault tolerant.
satya - 7/21/2017, 8:35:15 PM
Running distributed systems is very complex!!!
Running distributed systems is very complex!!!
satya - 7/21/2017, 8:44:43 PM
Few CLI operations
List and describe topics
Create new topics
Subscribe and consume topics
satya - 7/21/2017, 8:45:54 PM
Observability of Kafka
Observability of Kafka
satya - 7/21/2017, 8:46:50 PM
it has JMS: java clients are possible as well
it has JMS: java clients are possible as well
satya - 7/21/2017, 8:50:53 PM
Confluent cloud solution
Confluent cloud solution
satya - 7/21/2017, 8:52:42 PM
How does enterprise data interact with confluent cloud?
How does enterprise data interact with confluent cloud?
Search for: How does enterprise data interact with confluent cloud?
Will the data move from on premise to the cloud? And then back to the enterprise for consumption?
satya - 7/21/2017, 8:56:50 PM
Here is their CTO's pitch for the cloud
satya - 7/21/2017, 8:57:01 PM
What is kafka schema registry?
What is kafka schema registry?
satya - 7/21/2017, 9:07:26 PM
What are AVRO schemas
What are AVRO schemas
satya - 7/21/2017, 9:10:18 PM
How are AVRO schemas used in Kafka?
How are AVRO schemas used in Kafka?
satya - 7/21/2017, 9:11:01 PM
Kafka Tutorial: Kafka, Avro Serialization and the Schema Registry
Kafka Tutorial: Kafka, Avro Serialization and the Schema Registry
Search for: Kafka Tutorial: Kafka, Avro Serialization and the Schema Registry
satya - 7/23/2017, 11:59:39 AM
As Microsoft uses it on Azure: 2014

Notice it's parallels to Event Hubs. Notice its role in iOT as a storage and access mechanism to ordered and clustered events
satya - 7/23/2017, 12:00:26 PM
Microsoft brings real-time analytics to Hadoop with Storm preview
Microsoft brings real-time analytics to Hadoop with Storm preview
satya - 7/23/2017, 12:03:51 PM
The Brain of an IoT System: Analytics Engines and Databases: 2015
The Brain of an IoT System: Analytics Engines and Databases: 2015
satya - 7/23/2017, 12:11:46 PM
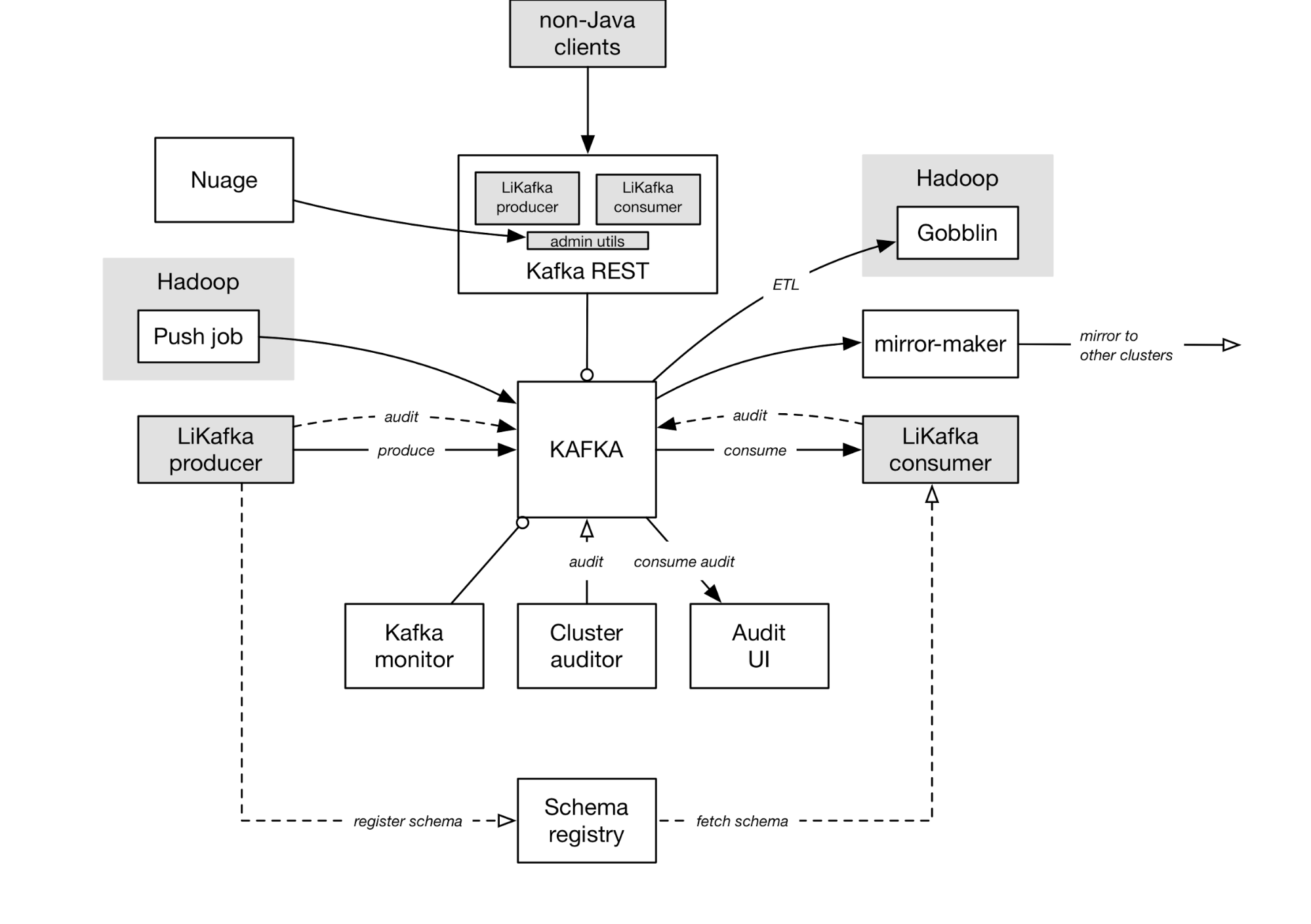
Linkedin Kafka ecosystem
satya - 7/23/2017, 12:12:19 PM
On Kafka brokers: 1400 at linkedin
We run several clusters of Kafka brokers for different purposes in each data center. We have nearly 1400 brokers in our current deployments across LinkedIn that receive over two petabytes of data every week. We generally run off Apache Kafka trunk and cut a new internal release every quarter or so.
satya - 7/23/2017, 12:13:25 PM
How schema registries are used
We - linkedin - have standardized on Avro as the lingua franca within our data pipelines at LinkedIn. So each producer encodes Avro data, registers Avro schemas in the schema registry and embeds a schema-ID in each serialized message. Consumers fetch the schema corresponding to the ID from the schema registry service in order to deserialize the Avro messages. While there are multiple schema registry instances across our data centers, these are backed by a single (replicated) database that contains the schemas.
satya - 7/23/2017, 12:14:36 PM
Interesting: Nuage
Nuage is the self-service portal for online data-infrastructure resources at LinkedIn, and we have recently worked with the Nuage team to add support for Kafka within Nuage. This offers a convenient place for users to manage their topics and associated metadata. Nuage delegates topic CRUD operations to Kafka REST which abstracts the nuances of Kafka?s administrative utilities.
satya - 7/23/2017, 12:14:56 PM
Lot of useful stuff here at the linked in to see how kafka is used
Lot of useful stuff here at the linked in to see how kafka is used
satya - 7/23/2017, 12:16:04 PM
whats up with Nuage
whats up with Nuage
satya - 7/23/2017, 12:29:39 PM
On Nuage at linkedin
Nuage is a service that exposes database provisioning functionality through a rich user interface and set of APIs. Through this new user interface, developers can specify the characteristics of the datastore they want to create, and Nuage will interact with the database system to provision your datastore on a pre-existing cluster.
The underlying database system needs to support multi-tenancy and needs to be elastic such that it can expand its capacity automatically when the load on the system increases.
It is ultra-simple to use and it takes little or no time to setup the data layer for the application you?re building.
It is elastic and scales automatically. New nodes are being provisioned automatically and as needed.
It has no single point of failure, is highly available, and fixes itself.
It is highly operable such that hundreds of thousands of nodes can be managed by a handful of administrators.