Hystrix: Netflix API stack at Netflix OSS
Hystrix is one of the API related tools at Netflix released as part of Netflix OSS. Allows you to compose auto-scaled container based services in a fault tolerant way using RxJava. Along with RxJava, Eureka, Archaiu, Ribbon, Zuul, Turbine, Karyon, Governator it provides a PAAS like environment for all of Netflix API and website needs. You will find here research and a bit of summary.
A simple proposition
If I have a database, writing an API against that database should be no more complicated than writing a select statement. This has been done more than once quite successfully. Container managed stored procedures is one example. An iPAAS like Dell Boomi is another example. More recently the iOT platform NodeRed comes to mind. I am sure there are countless examples more. I am sure there are a few draw backs in each of these solutions.
Then there is bending the world in this pursuit. Someone mentioned Hystrix. I got curious. Looked around. Here is a summary of this new fangled landscape. Let me first start with the ecoSystem and related names I have run into:
Hystrix: Frontends APIs for parallelism, scale, etc
RxJava: Programming model used by Hystrix
Eureka: Service discovery to tell Hystrix where the API is in a changing environment
Archaius: Distributed Configuration management
Ribbon: How all these components talk to each other over network: ipc
Zuul: All requests web and API enter here. Monitoring, security, routing
Turbine: Realtime metrics
Karyon: Template for the body of an API construction
Governator:Java utilities that makes up Karyon
Google Guice: Java utilities that are base for Governator
Kubernetes: A competing technology for service discovery
OpenShift:Along with kubernetes competes with much of this stack
Why the madness?
What am I missing? For what requirements these tools are necessary? So let me quickly go over the conceptual problem space of APIs. The following facilities are desirable depending the level of need:
1. They must run in auto-scaled environments. This means they cannot keep any local state.
2. They must be able to read their run time configuration from a distributed configuration services
3. The clients must be able to discover where the services are currently running
4. They must be able to compose other services either in parallel or in a reactive manner
5. Incoming threads should be closed if the service takes too long
6. Security must be able to be applied external to the service
7. Monitoring for real time analysis to alternately route the services
8. Documented
9. Mocked
10. Discoverable
11. Isolation for debugging
How does Netflix OSS API stack covers this landscape?
Many of these needs boil down to scaling the back ends of websites. Yes that gets you into APIs as well. Let me regurgitate conceptually what these technologies are trying accomplish.
When you write an API you want to write it in such a way that it is cloud ready. This means that code can be deployed and un-deployed at a moments notice in dynamically changing servers (containers). So any client that calls these services cannot be sure where they live. These services cannot rely on local state. So they need to register themselves when they are up so that they can be discovered (This is done through Eureka, a distributed registry for services. In case of OpenShift kubernetes does this through infrastructure tooling). The services need to read configuration values at run time. This is done through Archaius. (Some competing technologies are memcached, Redis, etcd ).
As every service needs to do these things they can use some common libraries. RxJava, Karyon, Governator, Google Guice are all utilities available to write such cloud ready services. Some competing technologies include SpringCloud.
Also the Netflix stack is very JVM centric. So it is specially optimized for Java, Scala, Groovy. On the other hand similar features could be expected for generic polyglot rest services through OpenShift.
Once such an API is constructed a client may discover and call it but the client may choose to a) call multiple APIs in parallel b) disconnect if it is taking too long c) Or provide an alternative implementation if unavailable etc. These aspects are handled by Hystrix when a client calls an API through Hystrix all of these concerns are handled without the client knowing about it. One can imagine Hystrix to be similar to an API manager except the scripting necessary for each API is custom.
Once you have the APIs are ?hystrified? requests can come in. But you want someone to monitor these incoming APIs, apply security, route them to servers based on load, collect stats etc. This is done through Zuul which itself uses Hystrix to do its job.
You also don?t want to log the traffic patterns in Hadoop and analyze later. You want to do this in real time and alter the traffic. This is done through Turbine.
Should API writing have to be this complicated?
No. A developer should be able to write very straightforward java code that manipulates other APIs or data. The underlying framework or platform should do the rest. This complexity need not be and should not be exposed to productive developers. It will unnecessarily tells graduates how complicated programming is. Hopefully clever developers can wrap these in their environments and provide that deep abstraction to end developers that you can just hire from most colleges.
Implications to containers like OpenShift
We got to see if there are answers to Zuul in openshift? Or will Zuul coexist with OpenSfhit? Is there an opportunity for Zuul to take the frontend security in most companies? Can Hystrix be adapted for OpenShift? Or is something in OpenShift that can already does what Hystrix does? Do we need Hystrix for ALL our APIs?
Implications to Boomi/NodeRed
Imagine, writing an API in this manner requires one to know, again, Lambda expressions, closures, RxJava, Google Guice, Archaius, Redis, Spring Cloud. That is not simplicity!! Do we need that for all cases? I don?t know! I hope not. But I could be wrong.
Dell Boomi and NodeRed are showing some good ways to write APIs. These frameworks encompass much of the wiring behind the scenes and in many cases provide a great compromise. Something to think about.
Implications to API Managers
Some of these requirements are also being addressed by API Managers like Apigee, Mashery, Mulesoft etc. However those concerns seem to be more around a) public APIs b) Meetering c) Discovery catalogues d) Security e) Documentation f) Mocking g) Monitoring etc. They are specifically not addressing scalability, circuit breakers, parallelism etc. This is a smaller subset. But in highly scalable scenarios these end up being primary concerns in production.
Are there actionable items
Ok I have read this. I am struggling to translate all this into actionalbe items. Here are some thoughts
1.See if you have an existing container like OpenSfhift and see how much of this can be accomodated in OpenShift. You already then have service discovery and distributed configuration management and auto-scaling
2.Find out by doing so will our services be simplified?
3.How do we best integrate or accomplish Hystrix like functionality on top of OpenShift?
4.Is there equivalent to Zuul in openshift?
5.What does our simple, medium, and complex API coding templates will look? Can we teach the corresponding coding techniques to a broader audience with examples and templates.
6. Can you write a library which allows a developer the same level of speed to market where the developer can move "10 lines of code" as an API instantaneously?
7. May be someone will build a platform where these technologies are behind the scenes and exposes
For now
It is likely that someone will emerge to provide an iPAAS that takes these into consideration.
Short of that senior architects in companies can strive for a few months to abstract these requirements into a framework on top of an existing container like openshift and provide that almost server-less-computing model where any computational logic can be deployed as an API in practically no time and written by novices.
satya - 7/25/2017, 10:07:08 AM
Netflix Hystrix - Latency and Fault Tolerance for Complex Distributed Systems: an article
Netflix Hystrix - Latency and Fault Tolerance for Complex Distributed Systems: an article
satya - 7/25/2017, 10:07:58 AM
Came out of Netflix API team in 2011
Came out of Netflix API team in 2011
satya - 7/25/2017, 10:23:59 AM
what is it briefly
Netflix has released Hystrix, a library designed to control points of access to remote systems, services and 3rd party libraries, providing greater tolerance of latency and failure.
satya - 7/25/2017, 10:26:08 AM
Premise
when an API fans out to many other apis, due to latency or failures, all waiting threads that run into this dependency can quickly block the whole server
Essentially all bad apples roost in the nest.
So detect the bad apples and yield.
satya - 7/25/2017, 10:26:23 AM
Hystrix and API managers
Hystrix and API managers
satya - 7/25/2017, 10:33:39 AM
Here is their crux
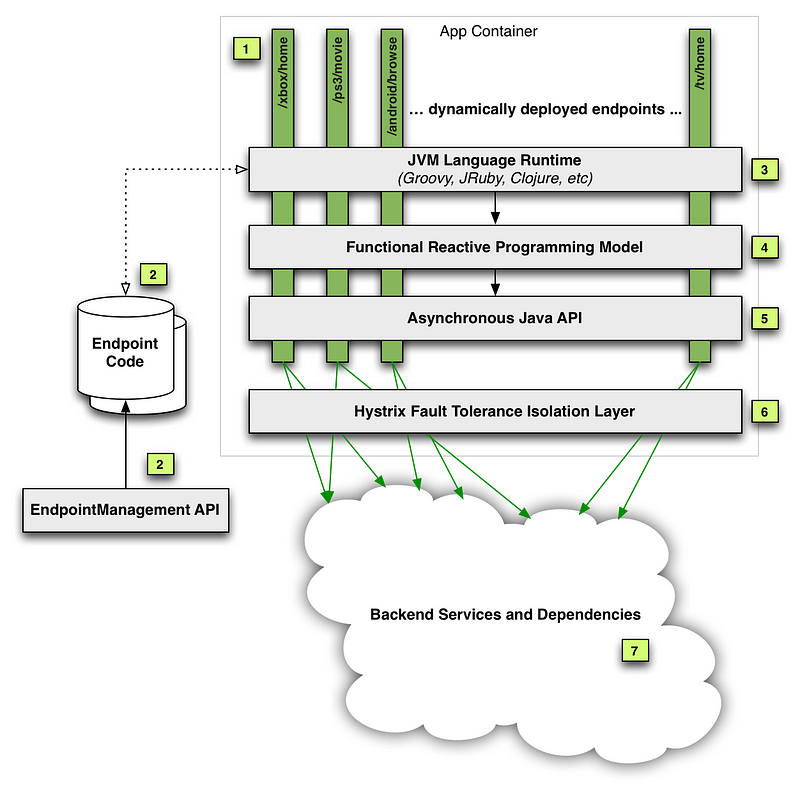
satya - 7/25/2017, 10:44:36 AM
Here is a PDF on netflix approach to cloud: 2013
satya - 7/26/2017, 7:10:54 PM
Hystrix EndpointManagement api
Hystrix EndpointManagement api
satya - 7/26/2017, 7:15:18 PM
Hystrix alternatives?
Hystrix alternatives?
satya - 7/26/2017, 7:15:25 PM
where is hystrix heading?
where is hystrix heading?
satya - 8/14/2017, 12:46:39 PM
Some notes on scale from Netflix Cloud presentation above
Thousands of:
- Instances
Hundreds of:
- Developers
- Applications
Dozens of:
- Engineering teams
- Deployments per day
Zero of:
- Architectural review committees
- Change review boards
satya - 8/14/2017, 12:49:13 PM
On Self service: netflix cloud
IMHO, self-service is the breakthrough characteristic of the cloud
Put security configuration in the hands of end-users, with some exceptions:
- SSL certificate management - Some firewall rules - User and permissions management
satya - 8/14/2017, 12:50:37 PM
Security Monkey
Designed to support culture of freedom and responsibility
Centralized framework for cloud security monitoring and analysis
Certificate and cipher monitoring
Firewall configuration checks and cleanup (with Janitor Monkey)
User/group/policy monitoring
satya - 8/14/2017, 12:53:38 PM
An image of that

satya - 8/14/2017, 1:16:37 PM
Netflix PAAS
Data Center
-> Cloud Architecture
Central SQL Database
-> Distributed Key/Value NoSQL
Sticky In-Memory Session
-> Shared Memcached Session
Chatty Protocols
-> Latency Tolerant Protocols
Tangled Service Interfaces
-> Layered Service Interfaces
Instrumented Code
-> Instrumented Service Patterns
Fat Complex Objects
-> Lightweight Serializable Objects
Components as Jar Files
-> Components as Services
satya - 8/14/2017, 1:20:43 PM
Bottom line of that deck from netflix
Be smart
Think for yourself
Optimize for what you need a) productivity b) speed to market c) scale d) and whatever else the situation demands
Blur the line between developers and administrators
Write code and not click buttons
Keep the prize in sight!
satya - 8/14/2017, 6:31:24 PM
Key features of Hystrix
Preventing any single dependency from using up all container (such as Tomcat) user threads.
Shedding load and failing fast instead of queueing.
Providing fallbacks wherever feasible to protect users from failure.
Using isolation techniques (such as bulkhead, swimlane, and circuit breaker patterns) to limit the impact of any one dependency.
Optimizing for time-to-discovery through near real-time metrics, monitoring, and alerting
Optimizing for time-to-recovery by means of low latency propagation of configuration changes and support for dynamic property changes in most aspects of Hystrix, which allows you to make real-time operational modifications with low latency feedback loops.
Protecting against failures in the entire dependency client execution, not just in the network traffic.
satya - 8/14/2017, 6:43:29 PM
Discovering services on the fly in netflix environment by clients: Eureka
Discovering services on the fly in netflix environment by clients: Eureka
satya - 8/14/2017, 6:47:36 PM
Alternatives to Hystrix
Alternatives to Hystrix
satya - 8/14/2017, 6:49:56 PM
Hystrix tools ecosystem
Hystrix tools ecosystem
satya - 8/14/2017, 6:51:49 PM
Here is the ecosystem for Hystrix at Netflix
The cloud platform is the foundation and technology stack for the majority of the services within Netflix. The cloud platform consists of cloud services, application libraries and application containers. Specifically, the platform provides service discovery through Eureka, distributed configuration through Archaius, resilent and intelligent inter-process and service communication through Ribbon. To provide reliability beyond single service calls, Hystrix is provided to isolate latency and fault tolerance at runtime. The previous libraries and services can be used with any JVM based container.
The platform provides JVM container services through Karyon and Governator and support for non-JVM runtimes via the Prana sidecar. While Prana provides proxy capabilities within an instance, Zuul (which integrates Hystrix, Eureka, and Ribbon as part of its IPC capabilities) provides dyamically scriptable proxying at the edge of the cloud deployment.
The platform works well within the EC2 cloud utilizing the Amazon autoscaler. For container applications and batch jobs running on Apache Mesos, Fenzo is a scheduler that provides advanced scheduling and resource management for cloud native frameworks. Fenzo provides plugin implementations for bin packing, cluster autoscaling, and custom scheduling optimizations can be implemented through user-defined plugins.
satya - 8/14/2017, 6:55:42 PM
So the tools
Eureka - Service discovery
Archaius - Distributed configuration
Ribbon - ipc
//Containers
Karyon
Governator
Prana
Zuul - serverless computing!!?
Fenzo - Scheduler for cloud native
satya - 8/14/2017, 6:57:14 PM
Hystrix and OpenShift
Hystrix and OpenShift
satya - 8/14/2017, 6:58:56 PM
Kubernetes and Eureka and Netflix OSS
satya - 8/15/2017, 9:16:18 AM
Related ecosystem of Hystrix
Kubernetes
Fabric
OpenShift
satya - 8/15/2017, 9:16:54 AM
OpenShift take on this
So can the infrastructure help out with service discovery, load balancing and fault tolerance also? Why should this be an application-level thing? If you use Kubernetes (or some variant), the answer is: yes.
satya - 8/15/2017, 9:37:17 AM
What is Zuul?
Zuul is the front door for all requests from devices and web sites to the backend of the Netflix streaming application. As an edge service application, Zuul is built to enable dynamic routing, monitoring, resiliency and security. It also has the ability to route requests to multiple Amazon Auto Scaling Groups as appropriate.
satya - 8/15/2017, 9:38:36 AM
Features of Zuul
Authentication and Security - identifying authentication requirements for each resource and rejecting requests that do not satisfy them.
Insights and Monitoring - tracking meaningful data and statistics at the edge in order to give us an accurate view of production.
Dynamic Routing - dynamically routing requests to different backend clusters as needed.
Stress Testing - gradually increasing the traffic to a cluster in order to gauge performance.
Load Shedding - allocating capacity for each type of request and dropping requests that go over the limit.
Static Response handling - building some responses directly at the edge instead of forwarding them to an internal cluster
Multiregion Resiliency - routing requests across AWS regions in order to diversify our ELB usage and move our edge closer to our members
satya - 8/15/2017, 9:40:23 AM
Zuuls relationship to other components
Hystrix: is used to wrap calls to our origins, which allows us to shed and prioritize traffic when issues occur
Ribbon: is our client for all outbound requests from Zuul, which provides detailed information into network performance and errors, as well as handles software load balancing for even load distribution
Turbine: aggregates fine�grained metrics in real�time so that we can quickly observe and react to problems
Archaius: handles configuration and gives the ability to dynamically change properties
satya - 8/15/2017, 9:46:38 AM
Karyon: A template for cloud ready webservice
Karyon: A template for cloud ready webservice
At Netflix, Karyon is a framework and library that essentially contains the blueprint of what it means to implement a cloud ready web service. All the other fine grained web services and applications that form our SOA graph can essentially be thought as being cloned from this basic blueprint.
satya - 8/15/2017, 9:46:57 AM
Karyon buildup
Bootstrapping , dependency and Lifecycle Management (via Governator)
Runtime Insights and Diagnostics (via karyon-admin-web module)
Configuration Management (via Archaius)
Service discovery (via Eureka)
Powerful transport module (via RxNetty)
satya - 8/15/2017, 9:47:37 AM
Governator: A utility on top of Google Guice
satya - 8/15/2017, 9:47:57 AM
Governator does
Classpath scanning and automatic binding
Lifecycle management
Injector bootstrapping
Configuration to field mapping
Field validation
Parallelized object warmup
Lazy singleton
Fine grained, more concurrent singleton
Generic binding annotations
satya - 8/16/2017, 10:04:07 AM
A quick look at the API space
| Feature | Tool Opportunity |
|---|---|
| Construction | Hystrix, Governator, Guice, RxJava, Camel, Apache CXF |
| Composition | Hystrix |
| Auto Scaling | OpenShfit |
| Configuration | OpenShift |
| Security | Not sure |
| Mocking | API Manager |
| Documentation | API Manager, Swagger |
| Monitoring | API Manager. May be Turbine can be examined to see if it can fit. |
| Debugging | Ability to route to a particular server for debugging purpose. May be the API manager. |
| Cataloguing | API Manager |
satya - 8/16/2017, 10:10:39 AM
Immediate opportunity
Looks like Hystrix, RxJava, Governator, Guice, Camel, Apache CXF can be immediately employed for API construction and composition, at least for Java.
satya - 8/16/2017, 10:35:17 AM
Also a monitoring question can be asked: Turbine
Is it appropriate during the construction of an API to raise monitoring events? And is Turbine worth looking at to do this?