Azure storage
Azure storage
satya - 8/18/2019, 5:18:57 PM
Here is a quick start on how to create Blob storage to keep files
Here is a quick start on how to create Blob storage to keep files
satya - 8/18/2019, 5:44:32 PM
Here are some sample CSV files from FSU: JBurkardt
satya - 8/18/2019, 5:46:14 PM
sample csv files to download
sample csv files to download
satya - 8/18/2019, 5:58:21 PM
All access to Azure Storage takes place through a storage account.
All access to Azure Storage takes place through a storage account.
satya - 8/18/2019, 6:04:18 PM
Storage accounts, containers, and blobs
satya - 8/18/2019, 6:09:35 PM
A storage account can contain zero or more containers
A storage account can contain zero or more containers. A container contains properties, metadata, and zero or more blobs. A blob is any single entity comprised of binary data, properties, and metadata.
The URI to reference a container or a blob must be unique. Because every storage account name is unique, two accounts can have containers with the same name. However, within a given storage account, every container must have a unique name. Every blob within a given container must also have a unique name within that container.
satya - 8/18/2019, 6:49:01 PM
Various parts of a Blob URI
https://myaccount.blob.core.windows.net/mycontainer/myblob
1. Storage account URI
2. container name
3. blob name
satya - 8/18/2019, 6:54:27 PM
Here is how to create a storage account
satya - 8/18/2019, 6:55:46 PM
Here is that screen
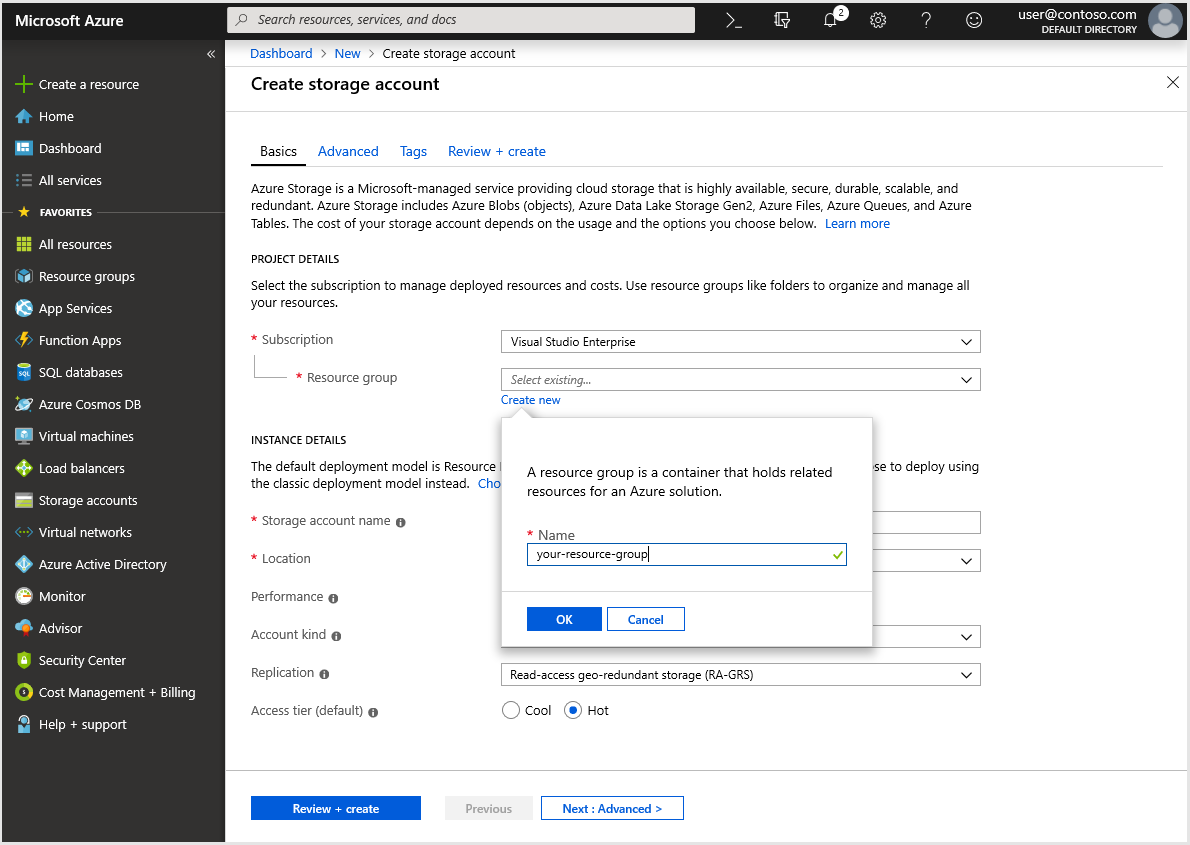
satya - 8/18/2019, 6:56:18 PM
Recommendation on take defaults
Deployment model Resource Manager
Performance Standard
Account kind StorageV2 (general-purpose v2)
Replication Read-access geo-redundant storage (RA-GRS)
Access tier Hot
satya - 8/18/2019, 6:58:18 PM
The default deployment model is Resource Manager, which supports the latest Azure features.
The default deployment model is Resource Manager, which supports the latest Azure features.
satya - 8/19/2019, 11:04:21 AM
Here is the hierarchy of blob storage
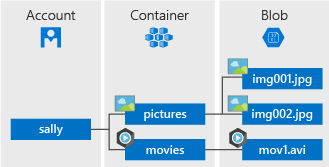
satya - 8/19/2019, 11:20:23 AM
How do I read an azure blob from databricks spark
How do I read an azure blob from databricks spark
Search for: How do I read an azure blob from databricks spark
satya - 8/19/2019, 11:20:56 AM
Here is a specific way to read using databricks
satya - 8/19/2019, 11:33:39 AM
Manage anonymous read access to containers and blobs
satya - 8/19/2019, 11:34:25 AM
Overview of Azure storage security
satya - 8/19/2019, 12:10:10 PM
What is done so far
Created a storage account to keep files for processing by Spark in data bricks. This is done in its own resource group.
Created a container.
Located a csv file and uploaded it as a blob in that container
There are some example of granting security at the "storage account" level using generated access keys and use that key for the spark cluster.
satya - 8/19/2019, 12:13:58 PM
However there are some annoying things
Securing the storage accounts, containers, files seem to have too many options. It is confusing
It is not clear how to provide fine grained security at container or file level. There are hints that one may have to use Active Directory. Then that leads identifying the clients (spark programs and clusters) to AD in some way. Not clear as well.
Databricks documentation seem to suggest things like DBFS, Shred keys, Pubic and private accounts etc. Too much stuff going on!
Wonder why is this more difficult then an "ftp" or a "database"! May be it is. Is that what the storage account is??
satya - 8/19/2019, 12:15:07 PM
next steps
I think I am going to use the access keys and then come back to these security concerns.
Use access keys in spark programs to read that CSV file and select a few columns and print them.
Then create a new CSV file that is a subset of the original CSV file using Spark
satya - 8/22/2019, 11:53:55 AM
How do I see my blob containers in a storage account?
Go to storage account
Then look below the detail of the account called "Services"
Locate Blobs
Click on it
It will take you to show a list of containers
Here you can view, delete, or create containers
Click on the container of your choice to see the blobs/files in that container
satya - 10/25/2019, 11:45:23 AM
How to create folders and sub folders in azure blob container
How to create folders and sub folders in azure blob container
Search for: How to create folders and sub folders in azure blob container
satya - 10/25/2019, 11:48:34 AM
As always SOF to the rescue: How to create sub directory in a blob container
As always SOF to the rescue: How to create sub directory in a blob container
satya - 10/25/2019, 1:17:29 PM
Naming standards for azure containers
Naming standards for azure containers
satya - 10/25/2019, 1:17:44 PM
How do I rename a container in azure?
How do I rename a container in azure?
satya - 10/25/2019, 1:19:06 PM
Apparently you cannot rename a container. See the SOF here
satya - 10/25/2019, 1:19:41 PM
Instead
Create a new container
Copy the blobs over
delete the old container
satya - 10/25/2019, 1:23:12 PM
There seem to be a way to do this with the azure storage explorer
However it may be doing behind the scenes the above procedure automatically
satya - 10/25/2019, 1:27:07 PM
Naming conventions for azure resources
satya - 10/25/2019, 1:31:43 PM
Looks like you can have policies to enforce naming